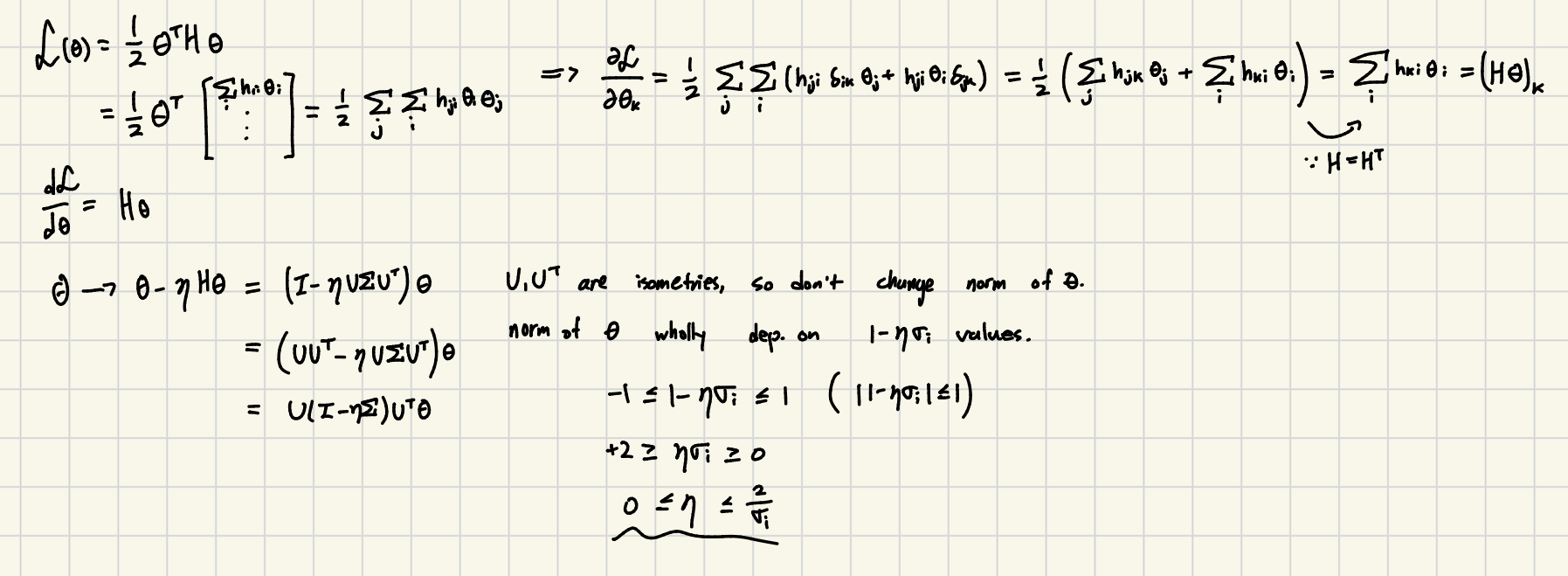simple setup
Consider a simple quadratic loss function for a model parameterized by , where is a symmetric positive semi-definite matrix (e.g., the Hessian):
Expanding this into summation notation:
the gradient
Taking the partial derivative with respect to using the Kronecker delta (and using the product rule):
Because is symmetric (), , we can simplify the expression to:
Thus, the full gradient vector is:
Taking the gradient of this expression, we can see that , or the Hessian of , is equal to .
maximal lr under GD
Applying the standard gradient descent update rule with learning rate :
Since is symmetric, we can decompose using its eigendecomposition , where contains orthogonal eigenvectors and is a diagonal matrix of eigenvalues . Substituting this into the update:
Since , we can rewrite the identity matrix:
Extracting the and terms,
Under this update, we have that
where the inner ‘s and ‘s cancel by orthogonality.
Clearly, if , the norm of will blow up and not be able to converge. So, for convergence, we need
Observe that under this constraint, will go to as . For our contrived loss , this is exactly what we want as the global minimum for this loss happens to be . In a more general setting, this might be more like the error in the parameters, i.e. , and we might look at the quadratic approximation for the loss near the minima.
Solving the inequality for :
To ensure stability across all dimensions, the learning rate is bounded by the steepest direction (the largest eigenvalue, ). The maximal stable learning rate is:
The maximal eigenvalue of , which is the Hessian of the loss, is equivalent to the sharpness of the loss. So, the punchline here is that the maximal stable learning rate is inversely proportional to the sharpness of the loss. This punchline holds as long as the Hessian of the loss is constant. However, clearly, for complex nonlinear models, this will not be the case. For neural networks, the “Edge of Stability” (EoS) phenomena suggests that during training, the sharpness of the loss progressively increases (progressive sharpening) until it saturates and hovers just around the value , the largest it can get without causing instability in training. This can be thought of as a kind of self-correcting, self-regulating behavior in neural nets.
disclaimer: this note was mostly transcribed by Gemini