Karkada et al. (2024) The lazy (NTK) and rich (µP) regimes: A gentle tutorial
Background
In When (wide) neural networks become linear, we saw that wide neural networks are approximately linear in their parameters. In particular, we saw that the empirical kernel corresponding to the model stays approximately constant throughout training such that the neural network essentially does kernel regression, i.e. linear regression in some high-dimensional projection space. This discovery was a big win for deep learning theorists as kernel regression is a well-studied machine learning algorithm. It allowed theorists to transfer insights from kernel regression to deep learning, shedding light on deep learning folklore for which researchers previously had no quantitative explanation. Some examples of such folklore:
- Neural networks fit real data faster than random noise: This is because the kernel of neural networks, i.e., the Neural Tangent Kernel (NTK), exhibits a “spectral bias.” It is highly biased towards fitting low-frequency functions (which typically represent real-world data) and struggles to fit high-frequency functions (like random noise) (Arora et al., 2019; Rahaman et al., 2019).
However, while the NTK and the lazy regime provided a mathematical lifeline for theorists, it soon became clear that it doesn’t capture the full magic of deep learning. In particular, we intuitively know that what’s special about neural networks is that they learn structure. In the lazy regime, the neural network acts merely as a static feature extractor, mapping data into a fixed high-dimensional space. The true power of deep learning, however, lies in feature learning (or representation learning). In practice, neural networks dynamically adapt their internal weights to discover useful hierarchical patterns, representations, and lower-dimensional structures inherent to the data. Concretely, there exist tasks for which “feature learning” is provably much more effective than lazy learning as shown by Damian et al. (2022).
So, how can we ensure that the network does feature learning? To operate in the “rich” or “active” regime, the network’s weights must be allowed to move significantly from their initialization during training. When the weights update meaningfully, the empirical kernel of the network actually evolves, adapting to the geometry of the target task rather than staying constant. To make sure this happens, we need to pay attention to the hyperparameters. It turns out, turning up the width is not the only way to get lazy learning, nor does infinite width fundamentally prevent feature learning. As we will soon find out, the line dividing the lazy and rich regimes is heavily dictated by the initialization scale and the learning rate.
Setup and Definitions
We consider a simple 3-layer linear network (simple, but not too simple) given by
such that at initialization, with a standard loss .
The parameters act as fixed gradient multipliers. Increasing while holding constant scales up the gradient for without altering the feedforward signal. Effectively, each layer gets its own learning rate.
Hidden representations are defined recursively as
where the base input is .
The dimension of each layer is denoted by . The network assumes a wide limit governed by a single scale .
Training Criteria (Constraints)
During training, the change in a layer’s representation breaks down into three distinct parts:
These terms represent the layer contribution, the passthrough contribution, and the interaction contribution.
We define well-behaved training as satisfying three core criteria:
- Nontriviality (NTC): .
- Useful Updates (UUC): for .
- Maximality (MAX): (this constraint ensures the layer contribution remains non-negligible).
The initialization scheme offers nine degrees of freedom:
- 3 variables,
- 3 variables,
- and 3 variables.
Satisfying the constraints will use 6 degrees of freedom:
- 1 from NTC,
- 3 from UUC,
- and 2 from MAX (since MAX is trivially satisfied for first layer).
This leaves three degrees of freedom. Two are used to fix the initial hidden activations and to be . The single remaining degree of freedom controls the richness of the training regime. In other words, enforcing the NTC, UUC, MAX, and fixing the initial hidden activations to be will imply that all the hyperparameters at initialization are completely determined by a single degree of freedom: the richness parameter.
Derivation
We begin with an initial forward pass. We will enforce that the hidden activations satisfy for ; i.e. that for .
Assuming the input scales as (which implies that ),
We want to enforce that , which would imply that . We enforce the same constraint for such that
Under the NTC, the final output cannot scale with width. This restricts the final layer to .
Next, we evaluate the backward pass. An omitted computation shows that
The chain rule yields . Taking the squared norm results in
Using equations (4) and (5), we can simplify the hidden representation updates significantly:
The MAX condition dictates that the layer term must not be dominated by the passthrough term. Thus, since the layer term aligns with , the update must also share this alignment. This simplifies the UUC to
Applying equation (7) to equation (5) gives
We already know for the hidden layers. Thus, the updates share a unified scale
Finally, we have all the equations we need to derive the scaling for all the hyperparameters at initialization. Enforcing the UUC,
Enforcing the MAX constraint on equation (7), we see that
Recall that for all , and that by the NTC, . This gives a piecewise scaling of :
We can then substitute these results back into our activation constraint from equation (3) and from equation (8). Doing so reveals
Thus, all initial hyperparameters are completely determined by the single degree of freedom , as desired.
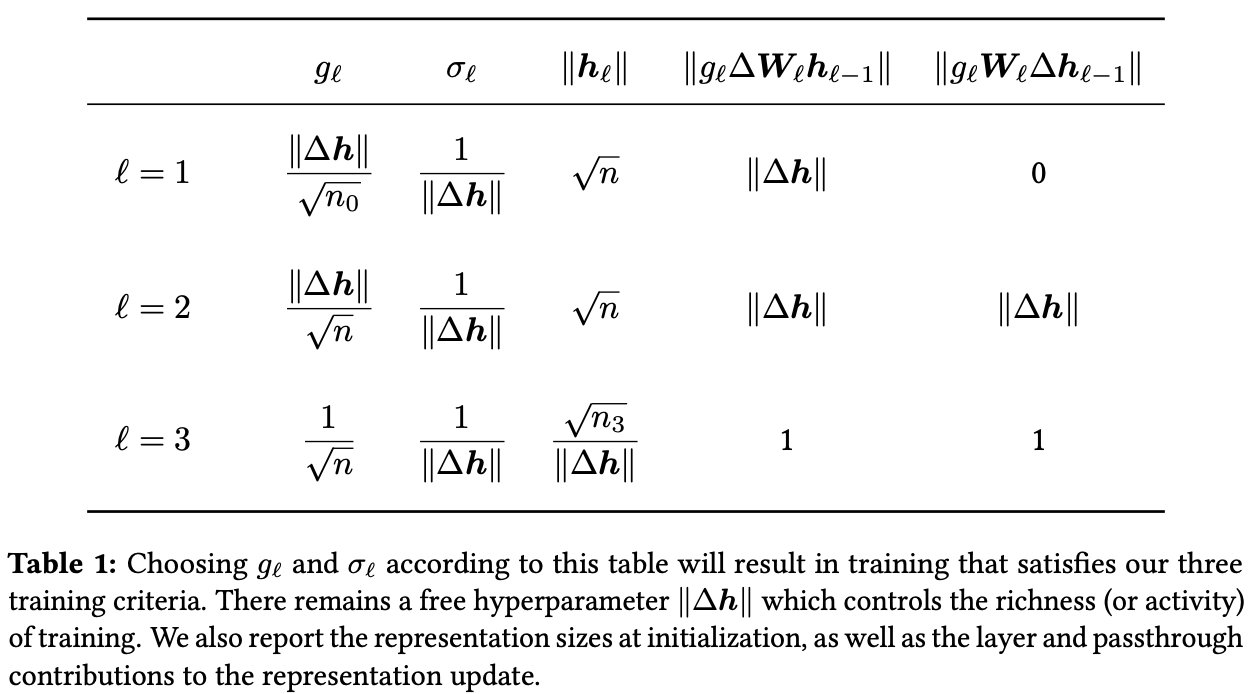
This defines the richness parameter , where and . The lower bound for comes from equation (3) while the upper bound is a reasonable heuristic. Theoretically and empirically, setting results in unstable training due to gradient instability.
disclaimer: this note was mostly transcribed by Gemini