Lack of Interpretability
The new paradigm of deep learning is inherently black-box. By leaving feature engineering to the model, we lose insight into the decision-making processes of the models. Despite the efforts to combat our lack of understanding, all interpretability techniques have flaws.
More troubling, though, is that a new understanding is emerging that deep neural networks function through the brute-force local interpolation of data points, rather than global fitting procedures (Hasson et al., 2020). This calls into question longheld narratives that deep neural networks “extract” high level features and rules. It also means that neural networks have no hope of extrapolating outside their training distribution. If not properly understood, current interpretability methods can lead to over optimistic projections about the generalization ability of a neural network.
Current interpretability methods such as saliency maps do not show the underlying decision processes of the model and leave too much room for subjective interpretation of the model’s generalization capabilities.
The author notes that one of the difficulties with interpreting deep neural nets and a large reason many interpretability techniques lead to bad interpretations is their inability to extrapolate and generalize.
Deep neural networks are are not akin to scientists finding regularities and patterns and constructing theories capable of extrapolating to new scenarios. Any regularities that neural networks appear to have captured internally are solely due to the data that was fed to them, rather than a self-directed “regularity extraction” process. It is tempting to tell “just-so” stories on how a deep neural network is functioning, based on one of the explainability techniques mentioned previously. These stories can mislead from what they are actually doing - which is fitting a highly flexible function to do interpolation between nearby points. Specific details of the architecture are not important - performance is largely a function of depth and how densely and broadly the data samples the real-world distribution of inputs.
Some researchers assert that we need not sacrifice accuracy for interpretability and that the “interpretability-accuracy” trade-off is an illusion. They suggest inherently interpretable models (eg. Self-Explaining Neural Networks) that could theoretically have similar capabilities as state-of-the art (SOTA) models. However, the author of this paper is skeptical that these inherently interpretable models will ever match the SOTA. He lists two reasons for his skepticism:
- “While it is true that the notion of such a trade-off is not rigorously grounded, empirically in many domains the state-of-the art systems are all deep neural networks. For instance, most state-of-art AI systems for computer vision are not interpretable in the sense required by Rudin. Even highly distilled and/or compressed models which achieve good performance on ImageNet require at least 100,000 free parameters (Lillicrap & Kording, 2019).”
- “some parts of the human brain appear to “black boxes” which perform interpolation over massive data with billions of parameters, so the interpretability of the brain using things like psychophysics experiments has come under question (Hasson et al., 2020). If evolution settled on a model (the brain) which contains uninterpretable components, then we expect advanced AIs to also be of that type.” Building on the second point, the author asserts that “If the world is messy and complex, then neural networks trained on real world data will also be messy and complex.” Perhaps adhering to inherently human-understandable architectures will overly constrain the space of possible models. It is entirely possible that to competently model our “messy and complex” world, we need “messy and complex” architectures.
The author notes that we as humans are able to communicate and trust each other despite not fully understanding the mechanisms of our brains. He asserts that we are able to do this because we are able to generate verbal explanations that make sense to others.
Crucially, for trust to occur we must believe that a person is not being deliberately deceptive, and that their verbal explanations actually maps onto the processes used in their brain to arrive at their decisions.
Thus, the author argues for the necessity of self-explaining AI. Specifically, he argues for mechanistic explanations.
Mechanistic explanations abstract faithfully (but approximately) the actual data transformations occurring in the model.
Self-Explaining Models
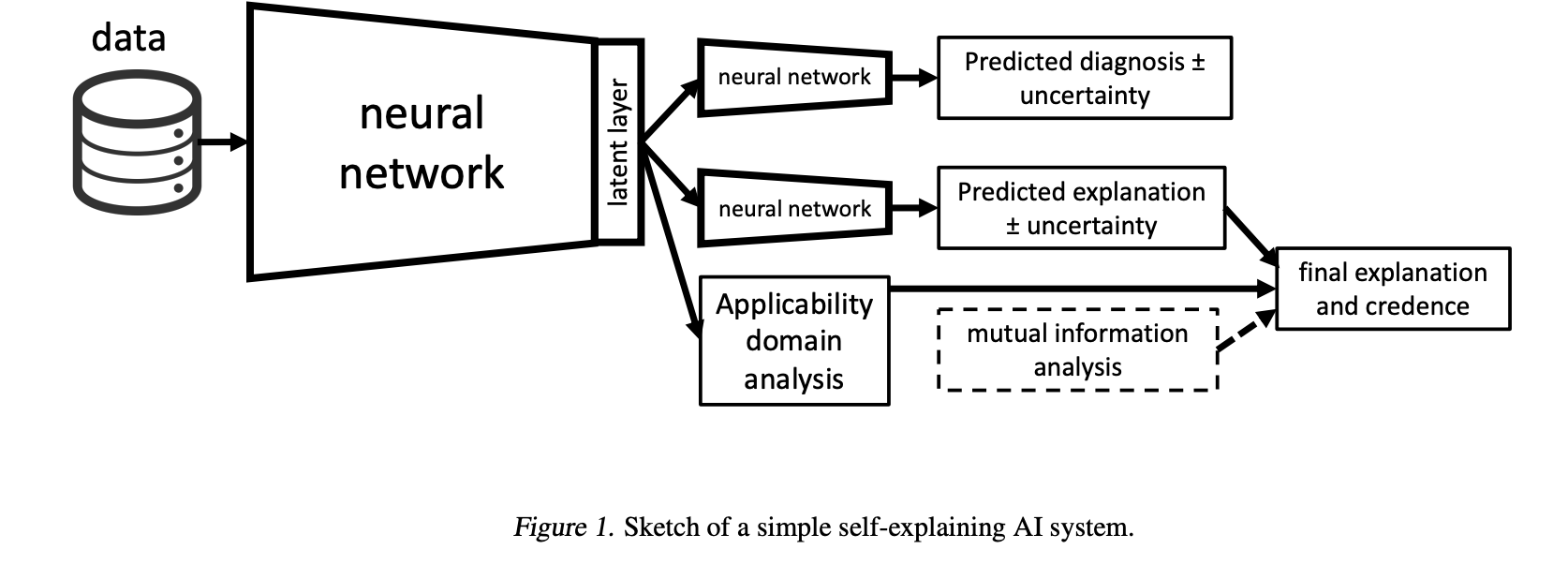
From Gemini: The paper proposes the concept of a “self-explaining AI” as an alternative to the pursuit of fully interpretable models. Such a system would produce two outputs: a prediction and an explanation of that prediction. The author outlines a framework for a trustworthy self-explaining AI, which should include at least three key components:
- A measure of relatedness: To ensure the explanation is genuinely connected to the model’s prediction, a metric like mutual information can be used. This helps verify that the explanation branch of the network is indeed influential in the decision-making process of the prediction branch.
We focus on the layer where the diagnosis and explanation branch diverge and look at how the output of each branch relates to activations in that layer. There are many ways of quantifying the relatedness of two variables, the Pearson correlation being one of the simplest, but also one of the least useful in this context since it is only sensitive to linear relationships. A measure which is sensitive to non-linear relationships and which has nice theoretical interpretation is the mutual information.
- Uncertainty quantification: The system should provide uncertainty levels for both its prediction and its explanation. This could be achieved using methods like Bayesian neural networks or dropout during inference, giving users a confidence level for any given output.
- An “applicability domain” warning system: The AI should include a “warning light” to alert the user when it is being asked to extrapolate beyond its training data. This concept, borrowed from other fields, involves defining the domain where the model can make reliable predictions and flagging inputs that fall outside this area.
This approach aims to build trust not by making the model’s internal workings completely transparent, but by providing verifiable explanations and a clear understanding of the model’s operational boundaries.
References: