The authors propose an ante-hoc explainability framework for training neural networks that are inherently interpretable. Evaluating based on explicitness, faithfulness, and stability, the authors show that existing methods for explainability are unsatisfactory. They propose SENNs and show that they are superior with respect to the aforementioned criteria.
From Linear Models to SENNs
The main intuition is that linear models are highly interpretable as we can see exactly what features the model is placing emphasis on, and they make consistent predictions based on a small number of parameters.
For input features , and associated parameters the linear regression model is given by . This model is arguably interpretable for three specific reasons: i) input features (’s) are clearly anchored with the available observations, e.g., arising from empirical measurements; ii) each parameter provides a quantitative positive/negative contribution of the corresponding feature to the predicted value; and iii) the aggregation of feature specific terms is additive without conflating feature-by-feature interpretation of impact.
The authors aim to generalize this kind of linear model to simultaneously enrich its learning capabilities while maintaining its interpretability. The generalization is achieved in 3 steps:
- Generalizing coefficients
- Utilizing rich feature bases
- Generalizing aggregation function.
Generalizing Coefficients
The idea is to have the coefficients depend on the input , i.e. have the coefficients be functions with respect to .
Specifically, we define (offset function omitted) , and choose from a complex model class , realized for example via deep neural networks.
Crucially, with just this generalization of , the model becomes “as powerful as any deep neural network” since could simply be a neural network. However, by doing so, we reintroduce black box neural nets and lose the interpretability that we had in scalar parameters. Thus, the authors assert that we must enforce “close” inputs and to have similar parameter values and .
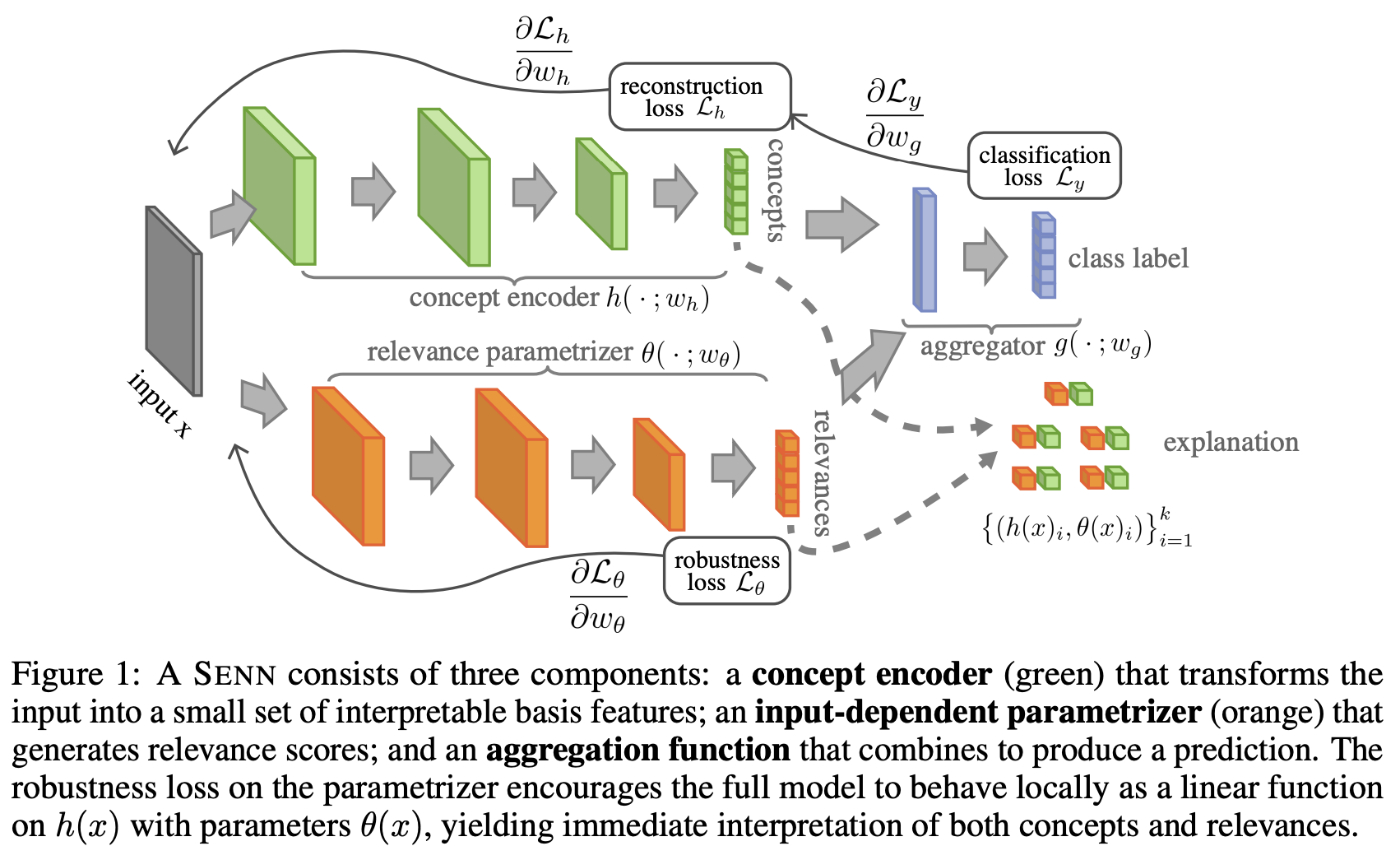
More precisely, we can, for example, regularize the model in such a manner that for all in a neighborhood of . In other words, ==the model acts locally, around each , as a linear model with a vector of stable coefficients ==. The individual values act as and are interpretable as coefficients of a linear model with respect to the final prediction, but adapt dynamically to the input, albeit varying slower than x.
Feature Basis
Typical interpretable models tend to consider each variable (one feature or one pixel) as the fundamental unit which explanations consist of. However, pixels are rarely the basic units used in human image understanding; instead, we would rely on strokes and other higher order features. We refer to these more general features as interpretable basis concepts and use them in place of raw inputs in our models.
We define a function that takes raw input features and projects them into a more interpretable feature space. The authors offer several suggestions for :
we consider functions , where is some space of interpretable atoms. Naturally, should be small so as to keep the explanations easily digestible. Alternatives for include: (i) subset aggregates of the input (e.g., with for a boolean mask matrix ), (ii) predefined, pre-grounded feature extractors designed with expert knowledge (e.g., filters for image processing), (iii) prototype based concepts, e.g. for some [12], or learnt representations with specific constraints to ensure grounding [19]. Naturally, we can let to recover raw-input explanations if desired.
With the generalized coefficients and the feature basis, we have the following model:
Since each remains a scalar, it can still be interpreted as the degree to which a particular feature is present. In turn, with constraints similar to those discussed above remains interpretable as a local coefficient. Note that the notion of locality must now take into account how the concepts rather than inputs vary since the model is interpreted as being linear in the concepts rather than .
Generalized Aggregation
The last step is to generalize the summation present in . We can consider more generally, any function that effectively aggregates the ‘s.
Naturally, in order for this function to preserve the desired interpretation of in relation to , it should: i) be permutation invariant, so as to eliminate higher order uninterpretable effects caused by the relative position of the arguments, (ii) isolate the effect of individual ‘s in the output (e.g., avoiding multiplicative interactions between them), and (iii) preserve the sign and relative magnitude of the impact of the relevance values .
Self Explaining Models
The authors use the following definition to enforce the notion of “local stability.”
Definition 3.2. is locally difference bounded by if for every there exist and such that implies .
The following definition defines the class of functions the authors constitute as self-explaining prediction models:
Definition 3.3. Let and be the input and output spaces. We say that is a self-explaining prediction model if it has the form where:
- P1) is monotone and completely additively separable
- P2) For every , satisfies
- P3) is locally difference bounded by
- P4) is an interpretable representation of
- P5) is small. In that case, for a given input , we define the explanation of to be the set of basis concepts and their influence scores.
Since our aim is maintaining model richness even in the case where the are chosen to be trivial input feature indicators, we rely predominantly on for modeling capacity, realizing it with larger, higher-capacity architectures.
The tricky part about enforcing P3 is that we want the model to be linear in terms of the concepts, not , i.e. we want to be stable with respect to .
For this, let us consider what would look like if the ’s were indeed (constant) parameters. Looking at as a function of , i.e. , let . Using the chain rule we get , where denotes the Jacobian of (with respect to ). At a given point , we want to behave as the derivative of with respect to the concept vector around , i.e., we seek . Since this is hard to enforce directly, we can instead plug this ansatz in to obtain a proxy condition: All three terms in can be computed, and when using differentiable architectures and , we obtain gradients with respect to (3) [above equation] through automatic differentiation and thus use it as a regularization term in the optimization objective. With this, we obtain a gradient-regularized objective of the form , where the first term is a classification loss and a parameter that trades off performance against stability—and therefore, interpretability— of .
This is so incredibly clever I’m at a loss for words. Essentially, we know we want to be true. We also know that . Since it’s difficult to directly encode the objective into the loss function, we instead encode into the loss function. A very nice problem-solving technique seen used in the wild!
Learning Interpretable Basis Concepts
Basis concepts which serve as “units” of explanation are ideally “expert-informed.” However, in cases where expert knowledge is scarce or expensive, such concepts can be learned. The authors propose the following desiderata for interpretable concepts:
(i) Fidelity: the representation of in terms of concepts should preserve relevant information, (ii) Diversity: inputs should be representable with few non-overlapping concepts, and (iii) Grounding: concepts should have an immediate human-understandable interpretation.
The authors then describe how they achieved their proposed desiderata:
Here, we enforce these conditions upon the concepts learnt by SENN by: (i) training h as an autoencoder, (ii) enforcing diversity through sparsity and (iii) providing interpretation on the concepts by prototyping (e.g., by providing a small set of training examples that maximally activate each concept). Learning of h is done end-to-end in conjunction with the rest of the model. If we denote by the decoder associated with , and the reconstruction of , we use an additional penalty on the objective, yielding the loss: Achieving (iii), i.e., the grounding of , is more subjective. A simple approach consists of representing each concept by the elements in a sample of data that maximize their value, that is, we can represent concept through the set where is small. Similarly, one could construct (by optimizing ) synthetic inputs that maximally activate each concept (and do not activate others), i.e., . Alternatively, when available, one might want to represent concepts via their learnt weights—e.g., by looking at the filters associated with each concept in a CNN-based . In our experiments, we use the first of these approaches (i.e., using maximally activated prototypes), leaving exploration of the other two for future work.
References: Towards Robust Interpretability with Self-Explaining Neural Networks