This paper attempts to create a more lightweight, transparent version of ProtoPNet.
The General Idea
To classify an input image, the model finds the Euclidean distance between each latent patch of the input image and the learned prototypes of images from different classes. The maximum of the inverted distances between a prototype and the patches of the input image is called the similarity score of the prototype. Note that the smaller the distance, the larger the reciprocal, and there will be only one similarity score for each prototype. Then the vector of similarity scores is multiplied with the weight matrix associated with the dense layer f to obtain logitis, which are normalized using Softmax to determine the class of the input image.
Other ProtoPNet models compare a prototype with a latent patch of x instead of a patch of x, where a latent patch is a part of the output of a baseline of the other ProtoPNet models. Therefore, Shallow-ProtoPNet does not lose any information between x and p due to the convolutional layers or pooling layers of any baseline.
Optimization Problem:
Architecture
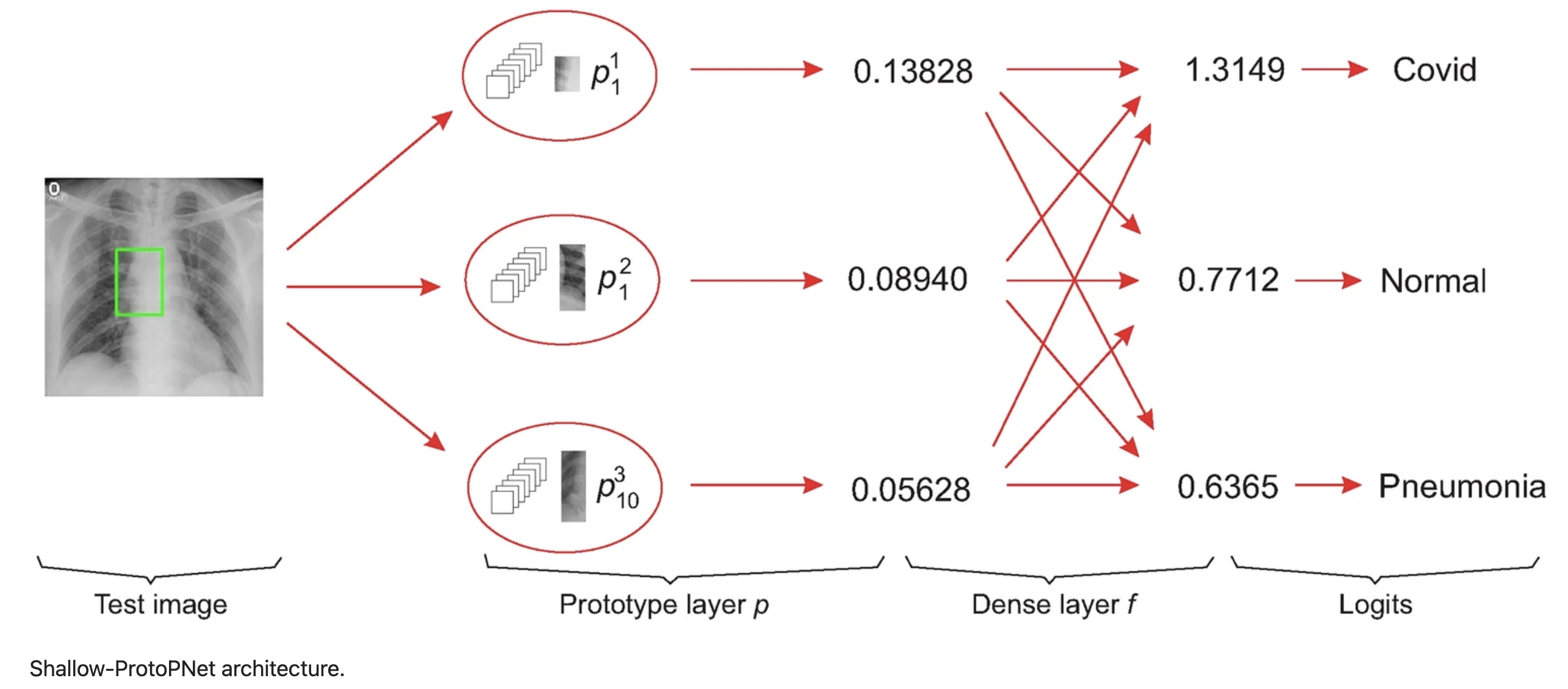
Simpler models are (almost always) necessarily more interpretable. This model is simple because it doesn’t use deep convolutional layers to generate latent representations and uses a simple convex dense layer with no biases. Because simplicity is so important for interpretability, it seems to me that in the process of developing an interpretable model for any given application, it makes sense to start with the simplest model and make it richer and more complex only if necessary.
In Towards Robust Interpretability with Self-Explaining Neural Networks, Jaakkola et al. suggest self-explaining neural nets. One of their key ideas is to have the relevance scores, i.e. the weights in the dense layer for this architecture, depend on the inputs. So, the weights in would be functions with respect to . Jaakkola et al. assert that although we want the feature basis to be simple for interpretability, in order to maintain model richness and complexity, we must rely on the relevance scores for modeling capacity. In this architecture, the weights in are held constant during inference. Allowing to depend on , i.e. training a separate model to learn the optimal , could potentially boost performance. Of course, this will certainly not work if the prototypes do not sufficiently capture the important information in .
In Interpretable Image Classification with Differentiable Prototypes Assignment, Rymarczyk et al. suggest using a pool of shared prototypes instead of assigning a certain number of prototypes to each class. Since there is no separability term in the loss function in ProtoPool, as opposed to the loss function in ProtoPNet, a shared pool of prototypes seems less necessary. However, it would definitely reduce redundancy in the model and perhaps make it more interpretable.
The term in the objective function, or the cluster cost, is there to ensure that the learned prototypes are “meaningful.” It forces every prototype to be similar (in the Euclidean distance sense) to some patch of a training example belonging to its class. I can imagine adding other regularization terms could be useful in shaping the prototypes to be useful and interpretable.
References: